A couple years ago, I took an undergraduate biostatistics course here at UC Berkeley and vividly remember one of the first discussion section activities on interpreting data and visualizations. From this activity, I learned about why, as data consumers, we must always be aware of not only what visualizations are really representing but also understanding where the data is really coming from. While this might seem obvious, this has been one of the most valuable lessons as an aspiring data scientist/enthusiast. I learned the importance of analyzing and understanding data with respect to context. Now, a couple years later, I went and conducted the same exercise with some of my friends. It went something like the following.
▪▪▪
The Activity
Step 1 - Take a look at this map. In this map, red areas are areas with median family income under the national average of $68,703 according to the 2019 US Census Bureau Report. Green areas are where the median household income is above the national average.
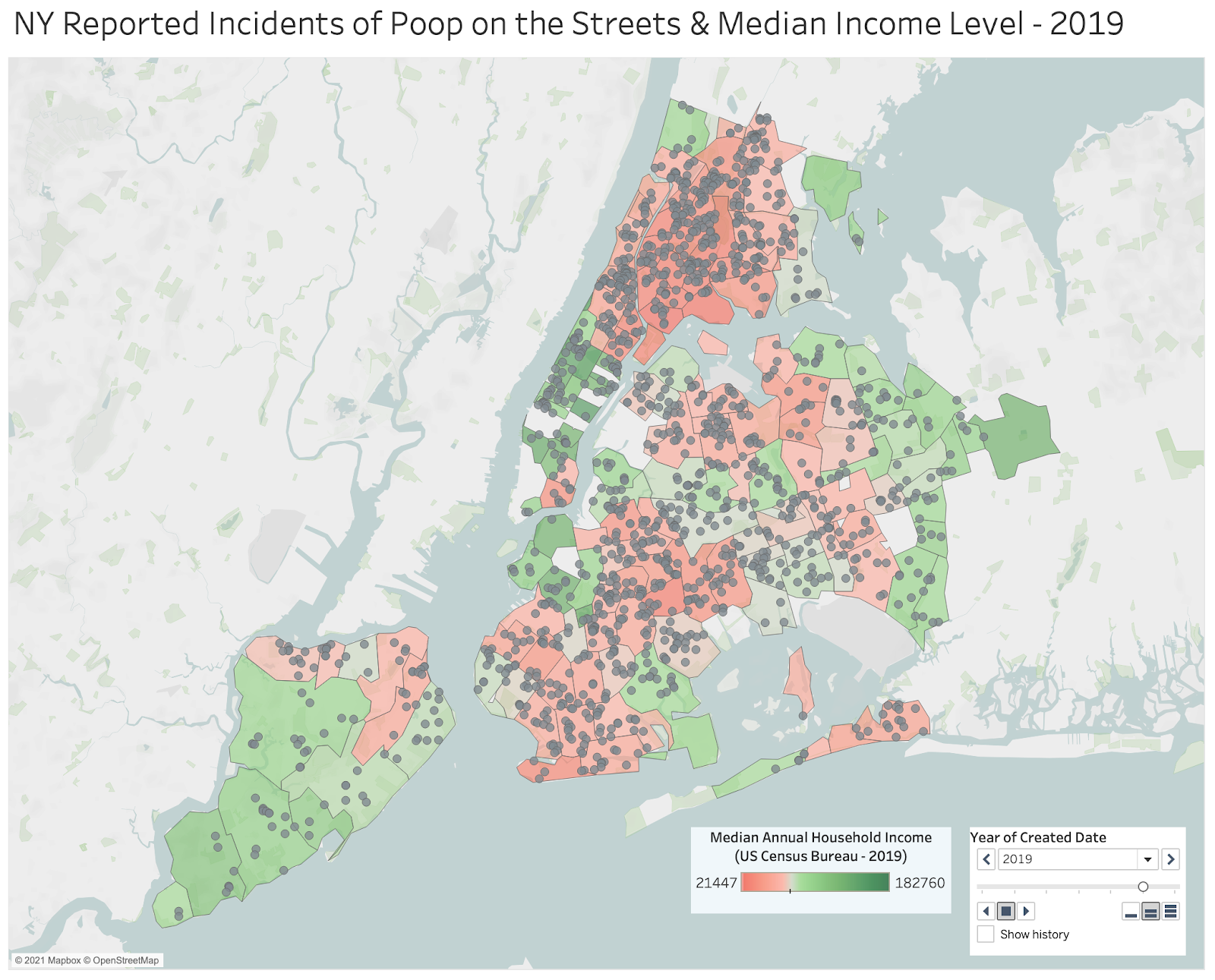
Step 2 - What is this map showing? Can you take anything away from this map? If so, what can you take away from this map?
▪▪▪
Let’s think about an observation that audiences might come to in step 2.
The most common comment shared in discussion was there were more incidences of poop on the streets in low income areas than high income areas perhaps due to a larger unhoused population in lower income areas and perhaps an unequal allocation of resources. This was very similar to the responses I gathered from friends and family (especially amongst those who did not have much exposure to data analysis or visualization). If we take a look at the map just at face-value this might make this claim seem valid. But, conclusions like these emphasize how important it is for analysts and for anyone presenting data to make intuitive, detailed visuals.
The map is actually a visual representation of all the reported incidents of DOG poop on the streets of New York. The data used to create this visualization was sourced from NYC 311 community reports of canine feces on the streets. Data available here.
Looking back, it seems obvious that there were questions that should have asked before even beginning to come to any conclusion. Even questions like, “What kind of data is this exactly?” and “Where did it come from?” were good starting points but were questions I overlooked. Those quick conclusions highlighted not only the need for increased data literacy in the general public, but also the importance of testing my visualizations to ensure the target audience’s takeaways align with my intended message.
While this is a pretty silly example, this activity prompted friends and classmates to start asking some probing questions before coming to any conclusion and prompted me to more actively engage with the data and the target audience to ensure that I do the data justice. Hopefully, this serves as a reminder to create visualizations and analyze data not just for those who interact with data on a daily basis.
